Dynamic global patch packing for video-based point cloud compression (V-PCC)
Chief investigator:
Yun-Zhan Tsai, Jui-Chiu Chiang
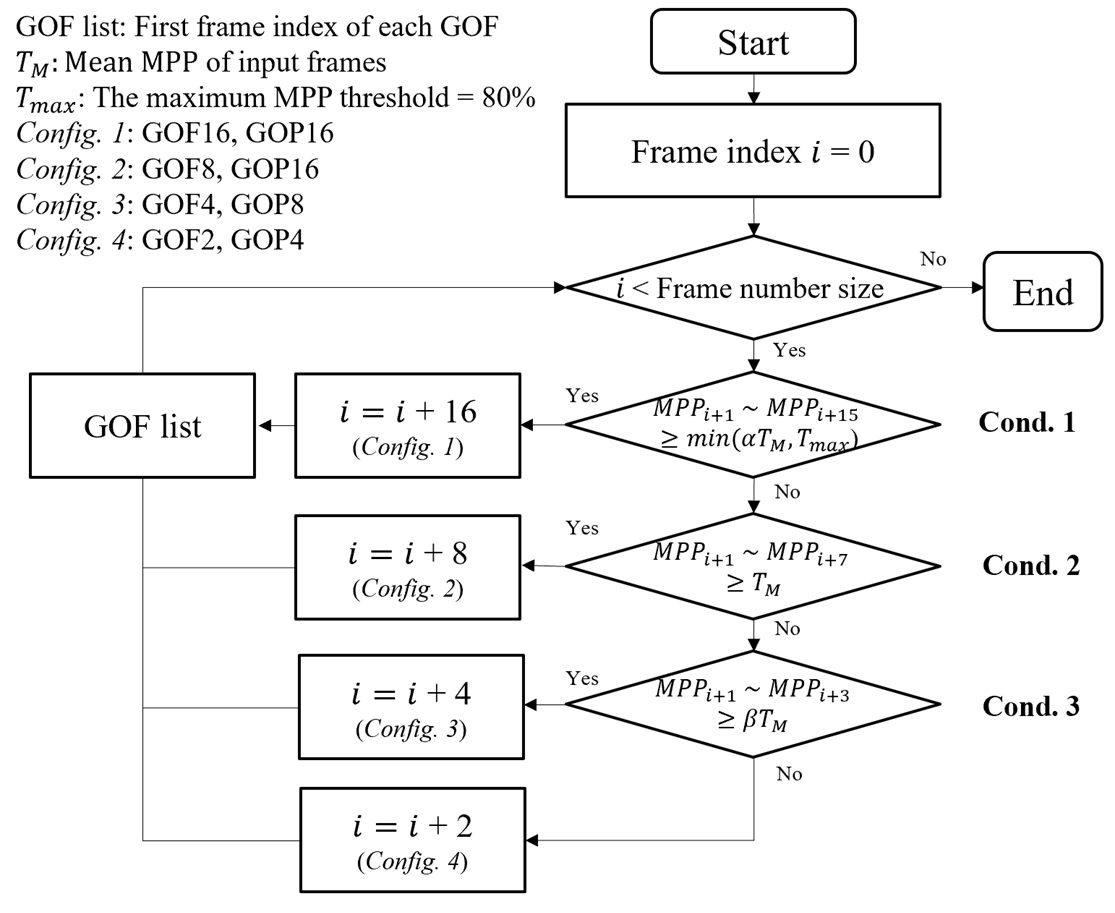
Fig. 1. The flowchart of the proposed dynamic group partitioning
ABSTRACT
Video-based point cloud compression (V-PCC) relies on a projection-based methodology that leverages established video compression techniques. To maintain temporal consistency within the packed images, V-PCC facilitates global patch packing solutions that aim to align corresponding patches across frames during the packing process. One such technique is global tetris packing (GTP), particularly efficient in scenarios with low motion activity within point cloud sequences. However, as the length of the point cloud sequence grows, accumulated motion within the input sequence can lead to increasing inconsistencies between patches across images, degrading the effectiveness of GTP. In this paper, we present a novel approach to enhance GTP. Our method measures the similarity between point cloud frames and dynamically partitions the sequence into variable groups of frames (GOFs). This strategy enhances temporal consistency within each group, thereby improving coding efficiency. Experimental results validate the superiority of our proposed technique over the anchor, delivering average BD-rate savings of 2.98%, 2.75%, and 1.39% for D1-PSNR, D2-PSNR, and Y-PSNR, respectively.
PROPOSED METHOD
We first identify two primary challenges encountered by GTP. First, in high-motion sequences, GMPP tends to be low, indicating insufficient temporal consistency for effective video coding. Second, there exists a noticeable lack of a strong positive correlation between patch weight and size within high-motion sequences. To address these issues, we propose a method to enhance GTP by dynamically partitions the input point cloud sequence into groups of frames (GOFs) with variable sizes. The objective is to achieve an increased GMPP within each GOF, compromising the compact packing and temporal consistency and consequently leading to improved coding efficiency. Besides, video coding typically employs group of picture (GOP) as the basic unit for encoding, it is then essential to jointly determine the dynamic GOF and the corresponding GOP to optimize the coding efficiency.
The flowchart of the proposed scheme is depicted in Fig. 1. We use MPP (representing patch coherence between consecutive frames) and  (containing global temporal consistency information) to partition the input sequence into GOFs with variable size. When a series of consecutive frames exhibit high MPP values, it suggests the use of a larger GOF. Considering that V-PCC supports a GOP size of up to 16 frames and one point cloud frame corresponds to two video frames, we have identified four configurations for the (GOF, GOP) pairs: (16, 16), (8, 16), (4, 8), and (2, 4). After computing the MPP for each frame, the proposed dynamic group partitioning is executed through multi-level decisions, progressing on three sequential conditions.
(containing global temporal consistency information) to partition the input sequence into GOFs with variable size. When a series of consecutive frames exhibit high MPP values, it suggests the use of a larger GOF. Considering that V-PCC supports a GOP size of up to 16 frames and one point cloud frame corresponds to two video frames, we have identified four configurations for the (GOF, GOP) pairs: (16, 16), (8, 16), (4, 8), and (2, 4). After computing the MPP for each frame, the proposed dynamic group partitioning is executed through multi-level decisions, progressing on three sequential conditions.
Condition 1: If MPP values for 2nd to 16th consecutive images are all larger than (α > 1), the config. (16, 16) is chosen. If not, check Condition 2.
Condition 2: If MPP values for 2nd to 8th consecutive images are all larger than , the config. (8, 16) is chosen. If not, check Condition 3.
Condition 3: If MPP values for 2nd to 4th consecutive images are all larger than (
The process to determine the size of GOF and GOP is recursively repeated until the final frame is processed. Subsequently, we compute the weight for each GOF sequentially, followed by GTP packing.
EXPERIMENTAL RESULTS
Our experiments follow the CTC of MPEG V-PCC. We encode five distinct sequences using 5 QPs. The values of α and β have been determined through empirical analysis and are set to 1.1 and 0.85, respectively. Fig. 2 shows the dynamic GOF distribution of 5 sequences. Notably, high motion sequences are divided into multiple GOFs, leading to a remarkable increase in GMPP and consequently enhancing temporal correlation within these sequences. In contrast, for the other three sequence, two GOF of size 16 are determined.
Table 1 presents the BDBR and BD-PSNR results of our method compared to the anchor GTP. In terms of D1-PSNR, D2-PSNR, and Y-PSNR, the proposed technique achieves average BD-rate savings of 2.98%, 2.75%, and 1.39%, respectively. Particularly for the high motion sequences, our approach exhibits outstanding performance. Furthermore, we conducted a comparison with GPA and the R-D performance is summarized in Table 2. The results show that the proposed method outperforms GPA for all the five sequence, achieving an average bitrate reduction of 4.80%, 4.4% and 3.33% for D1-PSNR, D2-PSNR, and Y-PSNR, respectively.
Additionally, our proposed approach ensures a strong positive correlation between weight and patch size. As depicted in Fig, 3 (b), we have increased the correlation between the weight with patch size, resulting in reduced image height and decreased encoding costs. The corresponding image height for the proposed technique are presented in Table 2, showcasing a substantial reduction in image height for high-motion sequences.
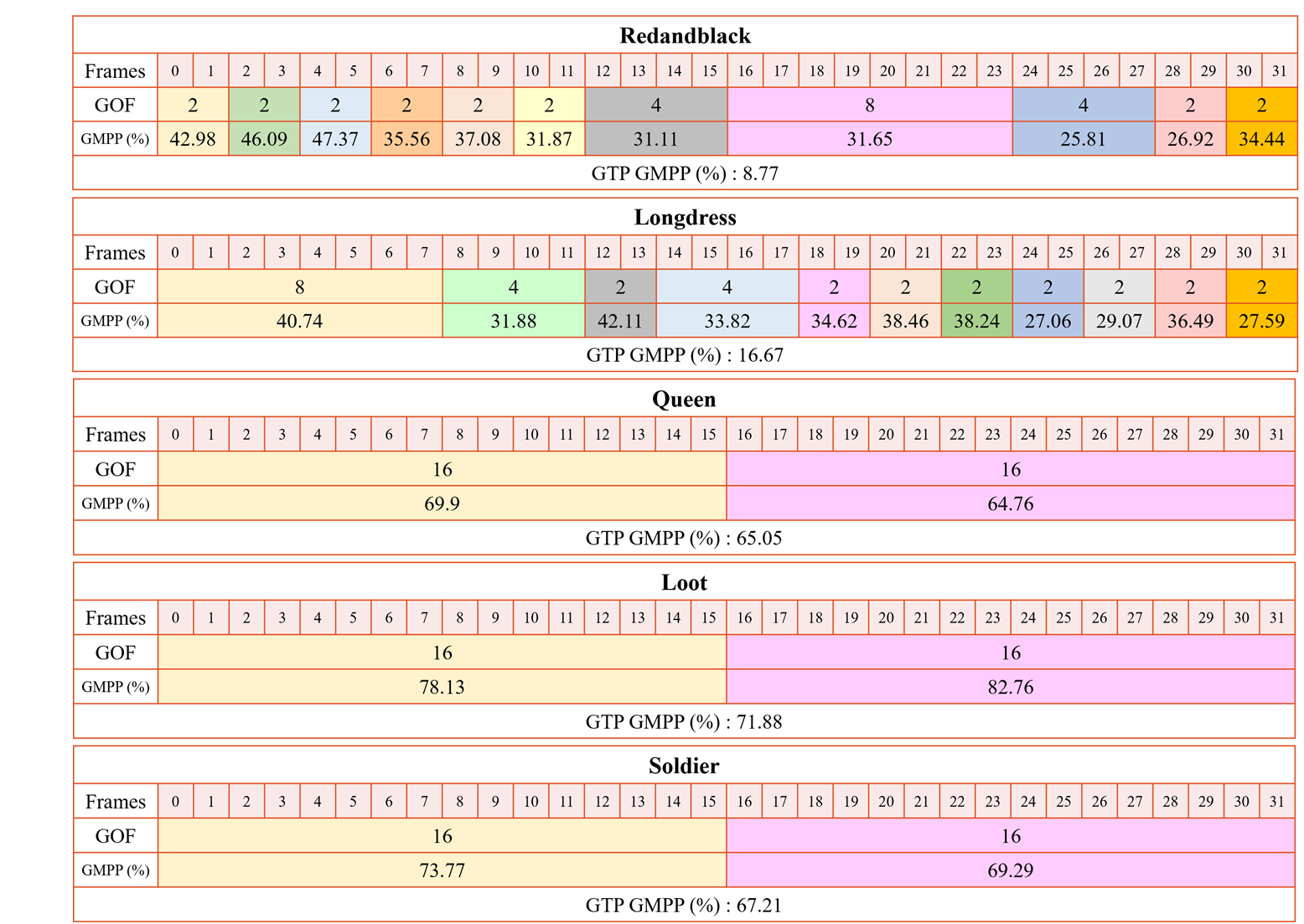
Fig .2. Dynamic grouping partitioning of 5 sequences.
Table 1. Proposed vs. GTP
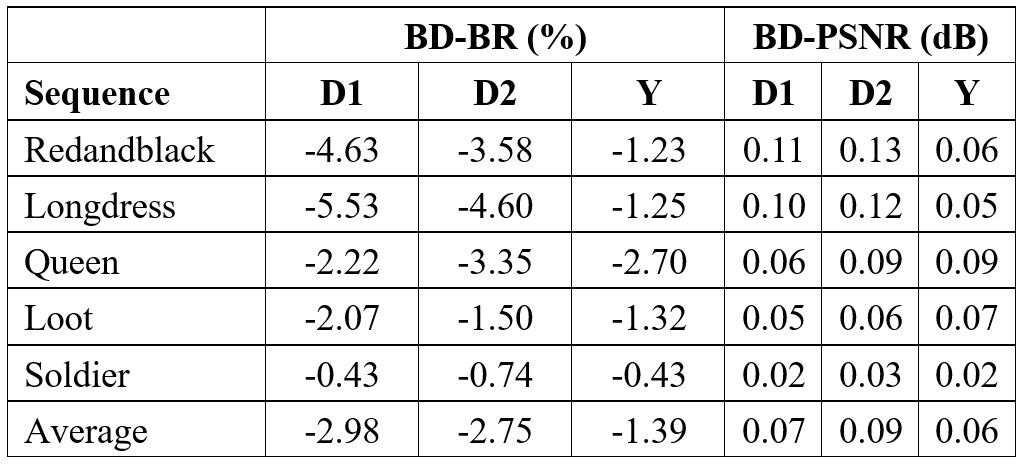
Table 2. Proposed vs. GPA
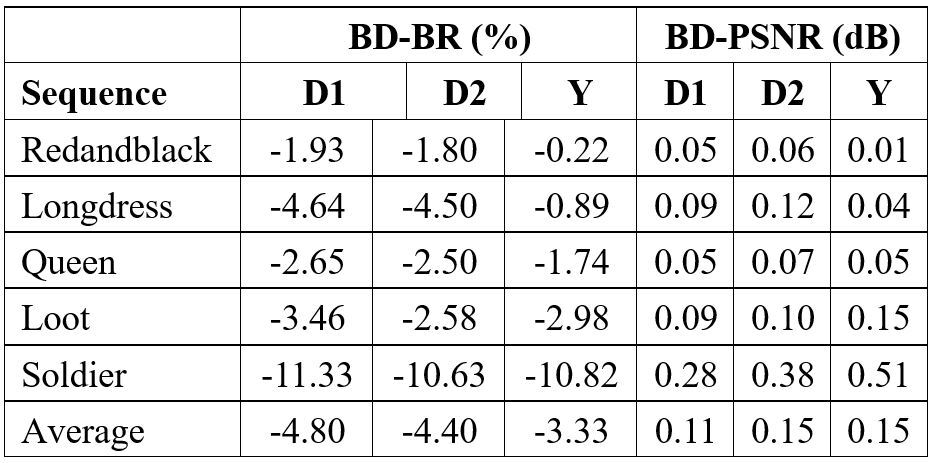
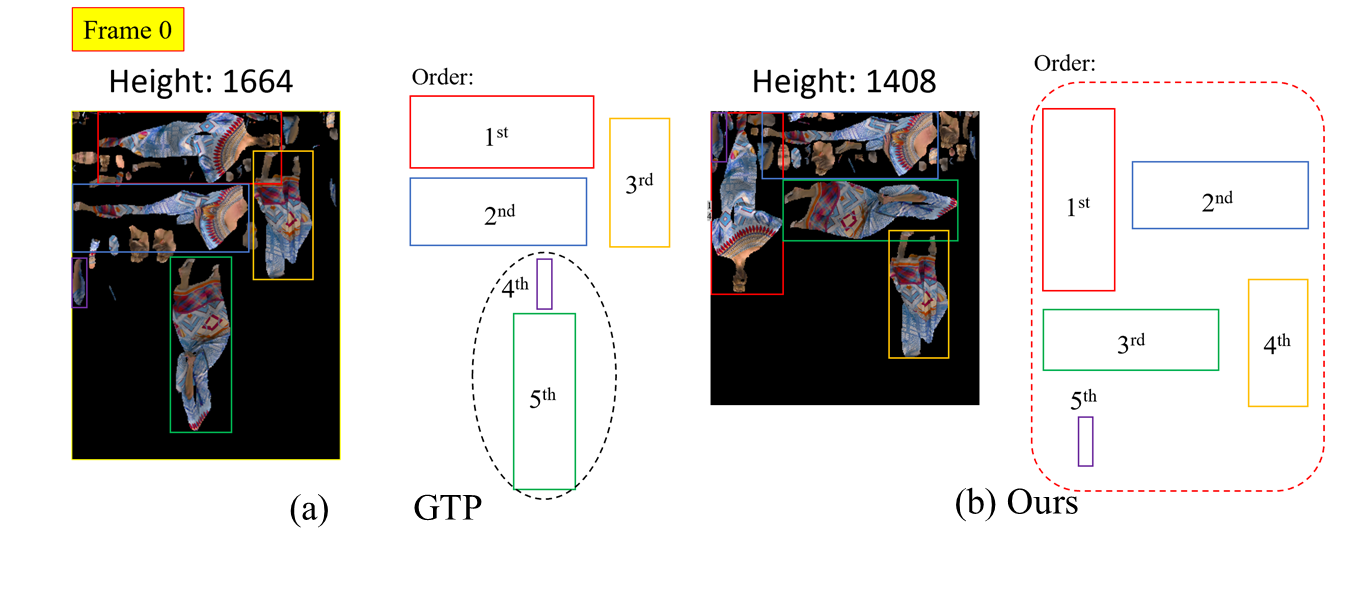
Fig. 3. Packed image of GTP and the proposed technique.