Efficient Mamba-based HDR Video Reconstruction with State Space Models
Chief investigater
Yu-Shan Lin, Jui-Chiu Chiang
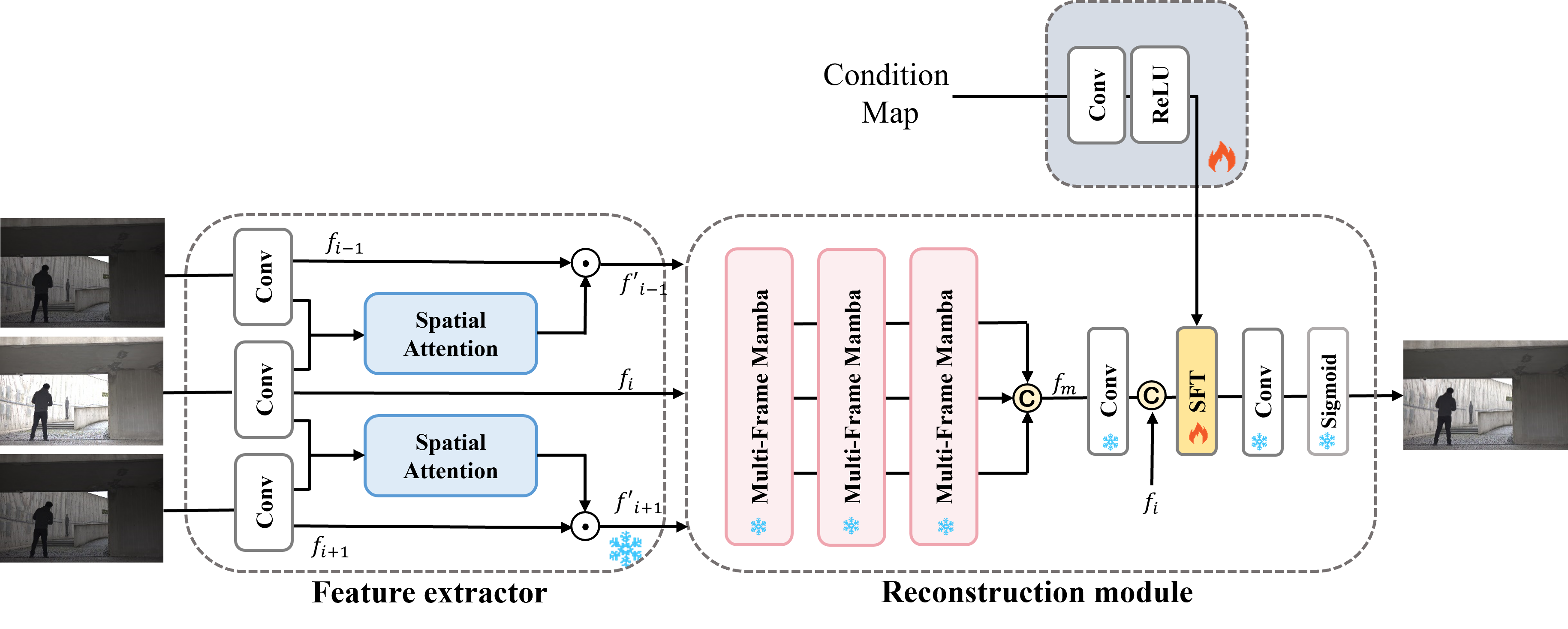
Fig. 1 Overall of the proposed architecture
Abstract
High dynamic range (HDR) video reconstruction remains a challenging task, particularly when dealing with dynamic scenes and moving objects, which can easily cause ghosting artifacts. While recent deep learning approaches have demonstrated possess deghosting capabilities, they often struggle with computational efficiency. In this work, we present HDRMamba, an architecture designed to address these limitations by leveraging State Space Models. Our method adopts an improved Mamba architecture, incorporating both spatial and temporal scanning mechanisms, which enable more efficient modeling of long-range dependencies across multiple frames while maintaining linear computational complexity. Additionally, we propose a prompt-tuning method that allows the model to adjust its features based on the exposure level of the input reference frame. Experimental results demonstrate that HDRMamba offers a solution that balances performance with efficient computation, making it a promising solution for real-world HDR video applications.
Proposed Method
Our network processes a sequence of LDR video frames {  |
|
 1,…n}captured with alternating exposures {
1,…n}captured with alternating exposures {  | 1,…n}by a standard camera. In this sequence, each LDR frame is captured at one of two alternating exposure settings. Based on these input LDR frames, our objective is to reconstruct the corresponding HDR frames{
| 1,…n}by a standard camera. In this sequence, each LDR frame is captured at one of two alternating exposure settings. Based on these input LDR frames, our objective is to reconstruct the corresponding HDR frames{  | 1,…n}.
| 1,…n}.
A. Pre-processing
For a given input sequence with corresponding exposure times, we first convert each frame to the linear HDR domain. This conversion, inspired by [6], applies gamma correction and exposure compensation:
![]() (1)
(1)
where  set as 2.2. We then concatenate each original LDR frame with its pseudo HDR version, creating a 6-channel input. Our network processes a triplet of consecutive frames{
set as 2.2. We then concatenate each original LDR frame with its pseudo HDR version, creating a 6-channel input. Our network processes a triplet of consecutive frames{  ,
,  ,
,  }to reconstruct the central HDR frame, where
}to reconstruct the central HDR frame, where  is middle reference frame.
is middle reference frame.
B. Pipeline
Our proposed architecture, illustrated in Fig. 1, employs a two-stage training process. The first stage involves pre-training an end-to-end HDR video reconstruction model. The initial component of our network is the feature extractor. This module starts by independently processing each input image through convolutional blocks , which consist of one 5x5 convolution followed by three 3x3 convolutions, to obtain the shallow features {  ,
,  ,
,  }. Following feature extraction, we apply a spatial attention module inspired by AHDRNet [9] to extract coarser features. These features are then embedded and passed to the Mamba-based reconstruction network, which produces the final HDR image. The second stage introduces a condition network and a spatial feature transform (SFT) Module. The condition network provides additional contextual information that enhances the performance of the HDR reconstruction.
}. Following feature extraction, we apply a spatial attention module inspired by AHDRNet [9] to extract coarser features. These features are then embedded and passed to the Mamba-based reconstruction network, which produces the final HDR image. The second stage introduces a condition network and a spatial feature transform (SFT) Module. The condition network provides additional contextual information that enhances the performance of the HDR reconstruction.
C. Spatial Attention Module
Spatial attention module processes pairs of frames: a non-reference frame and the reference frame, as shown in Fig. 2. By comparing these frames, it generates an attention map that weights features from the non-reference frame. This mechanism suppresses misaligned or saturated areas in non-reference frames, which could otherwise cause ghosting artifacts. Simultaneously, it emphasizes useful information from non-reference frames when the reference frame contains saturated or noisy regions. The module outputs weighted features  and
and  for the preceding and following frames respectively.
for the preceding and following frames respectively.
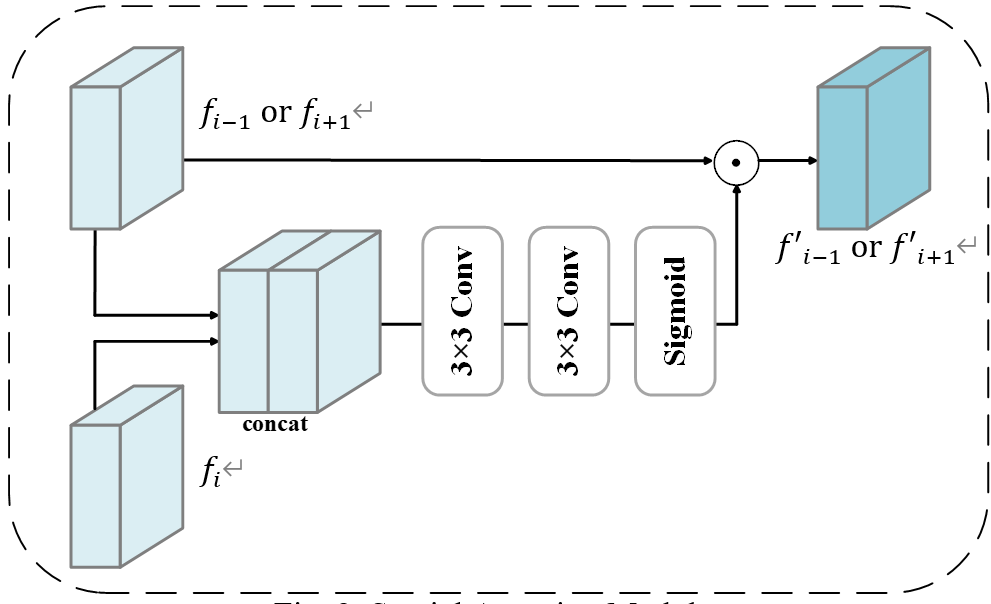
Fig. 2 Spatial Attention Module
D. Multi-frame Mamba Block
Recent advancements in addressing the high complexity of long sequence modeling have led to the development of Mamba [10], inspired by state space models (SSMs). Mamba's core idea is to effectively capture long-range dependencies in one-dimensional sequences through a selective scanning mechanism. Building on this, we introduce the multi-frame Mamba block, as shown in Fig. 3, which extends the four-directional spatial scanning mechanism proposed in VMamba [11] by incorporating the cross-frame spatiotemporal scanning. Traditional state-space models (SSMs) struggle to fully exploit temporal-spatial relationships in image/video due to their reliance on sequential scans of current and previous data. To overcome this limitation, we introduce the multi-frame Mamba block which incorporates both intra-frame and cross-frame analysis. An intra-frame four-directional SSM enhances spatial understanding within each frame, while a cross-frame bidirectional SSM captures temporal dependencies by analyzing data across multiple frames in both forward and backward directions. This combined approach allows the Mamba block to effectively leverage both spatial and temporal information, resulting in improved image processing capabilities. In the proposed Mamba block, image features are split into disjoint 8×8 patches through patch embedding. The intra-frame four-directional SSM applies four parallel S6 blocks along different traversal paths within each frame. This approach allows each pixel to integrate information from all other pixels in various directions, effectively establishing a global receptive field in 2D space. The cross-frame bidirectional SSM introduces a novel approach for temporal sequence processing. It performs bidirectional scanning across frames, allowing each pixel to integrate information from corresponding pixels in both past and future frames. This bidirectional nature enables the model to capture complex temporal dependencies, which is crucial for maintaining consistency and handling dynamic scenes in HDR video reconstruction. Finally, the patch sequence is reshaped and combined to create the output feature. By combining these spatial and temporal scanning mechanisms, our multi-frame Mamba block effectively captures the intricate relationships in HDR video sequences.
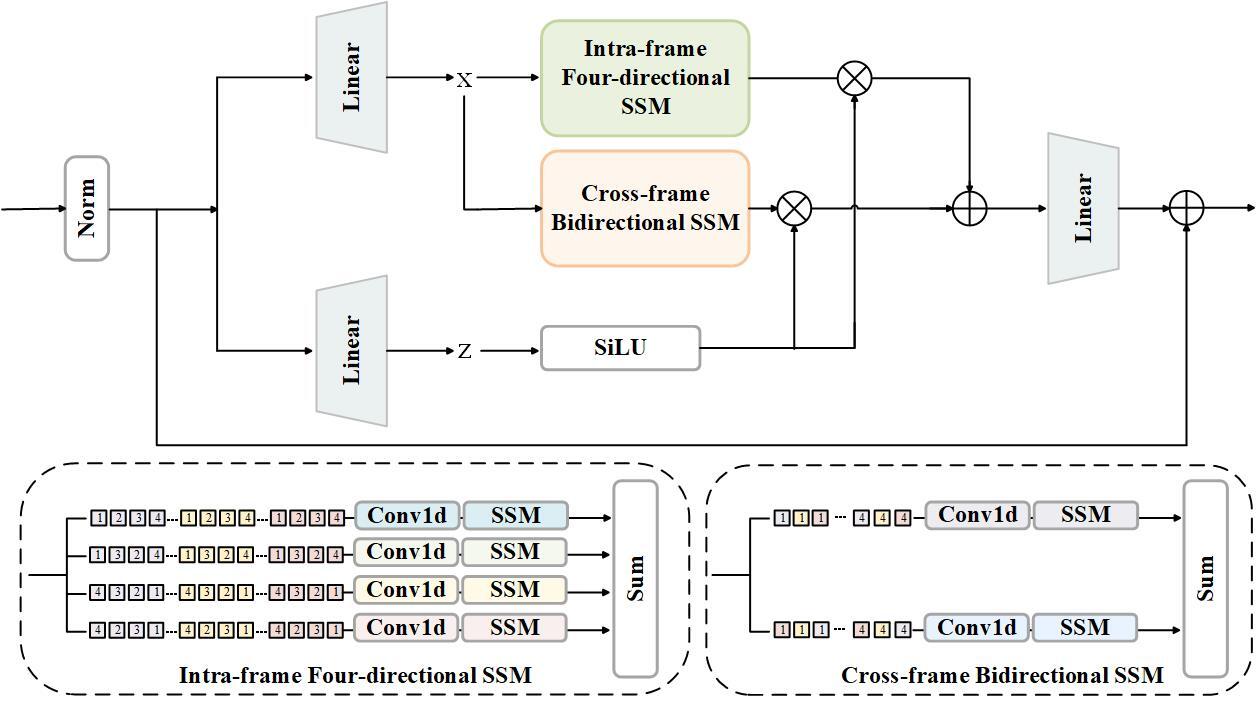
Fig. 3 Multi-frame Mamba Block
E. Condition Network
To adapt our model to varying exposure conditions, we introduce a condition network. This network takes a condition map as input, which has the same resolution as the input image. The condition map's values are determined by the exposure level of the image. The condition network processes this map through a 3x3 convolutional layer, and its output is then fed to the spatial feature transform module.
F. Spatial Feature Transform Module
Inspired by [12], we introduce a spatial feature transform (SFT) module that dynamically adjusts feature processing based on each image's exposure. The SFT module generates element-wise scale (γ) and shift (β) parameters, which are used to adjust features from the preceding layer. As illustrated in Figure 4, these parameters allow the network to scale and shift each feature channel independently, adapting to different exposure levels. For instance, in highly exposed areas, γ might reduce feature values to recover highlight details, while in underexposed areas, it might amplify them to enhance shadows. Similarly, β can shift feature values to fine-tune the network's response to different exposure levels. This adaptive transformation enables our network to effectively handle varying lighting conditions, a key challenge in HDR video reconstruction.
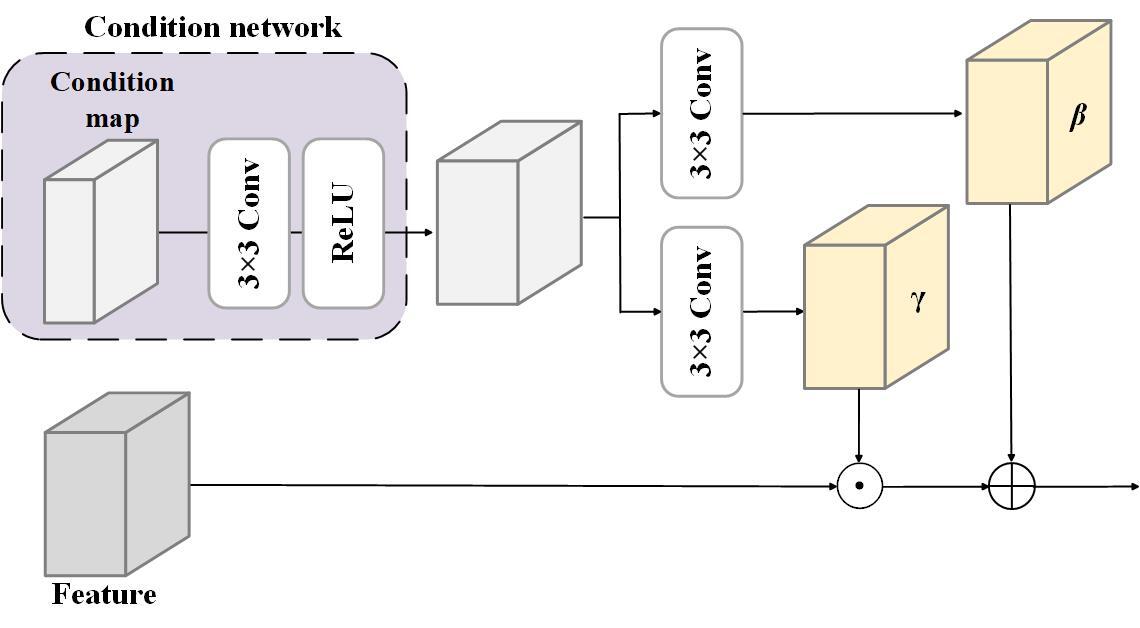
Fig. 4 Spatial Feature Transform Module
Experiment
In this section, we evaluate the performance of our method by comparing it with state-of-the-art HDR video reconstruction methods. For training, we utilized the Real-HDRV dataset [8], which contains sequences of images with two alternating exposures, featuring different kinds of motion and various scenes. The dataset comprises 450 training videos and 50 testing videos. Additionally, we conducted evaluations using the Chen21 dataset [6] to further validate the effectiveness of our approach in diverse scenarios. We utilize the metrics PSNR-T and SSIM-T, which are PSNR and SSIM values in the µ-law tone-mapped domain, alongside PU-PSNR, PU-SSIM, LPIPS, HDR-VDP-2, and HDR-VQM for our evaluations. For the HDR-VDP-2 metric, we simulated viewing conditions on a 24-inch display in an office daylight environment, with a viewing distance of 0.5m.
A. Training details
In the first stage, we train the network for 100 epochs to establish baseline HDR reconstruction capabilities. Following this, we conduct a second stage of training for an additional 30 epochs. To efficiently utilize our training data, we sample 256 × 256 patches from the training images using a stride of 384 pixels. For optimization, we employ the Adam optimizer with hyperparameters β_1= 0.9 and β_2 = 0.999. We initialize the learning rate at 2e-4 and implement a learning rate decay strategy, halving the rate every 100 epochs.
B. Quantitative Results
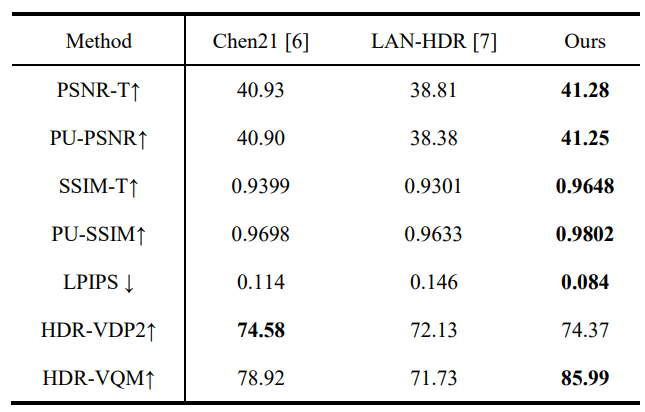
Tab.1 presents a quantitative comparison between our HDRMamba method and other state-of-the-art approaches, showcasing the effectiveness of our model in HDR video reconstruction. Our method shows notable improvements, achieving higher scores in both PSNR and SSIM metrics, which indicate better overall reconstruction quality and structural similarity to the ground truth. Our lower LPIPS score suggests that our reconstructions are perceptually closer to the ground truth, potentially offering more visually pleasing results to viewers. The improvement is particularly evident in the HDR-VQM score, where we achieve a considerably higher value, indicating better quality in the HDR domain. While our HDR-VDP2 score is slightly lower than Chen21's, the difference is minimal, and we outperform in all other metrics. This suggests that our method maintains excellent visibility prediction while excelling in other aspects of HDR reconstruction.
TABLE. 1 Comparison results with state-of-the-art methods.
C. Qualitative Results
Fig. 5 provides a visual comparison of our HDRMamba method against other approaches. In the top row, where the input frame has low exposure, our method demonstrates a remarkable ability to recover genuine information in occluded areas. This stands in stark contrast to the other two methods, which exhibit severe ghosting artifacts. For instance, LAN-HDR produces noticeable green ghosting effects, while Chen21's approach results in reddish artifacts. Our HDRMamba, however, manages to reconstruct these areas with greater accuracy and fewer distortions. The bottom row showcases our method's effectiveness in handling high-exposure input frames. Here, HDRMamba excels in recovering fine details in bright areas of the scene, particularly evident in the texture of overexposed building facades. In comparison, LAN-HDR struggles with these high-exposure regions, resulting in overexposed areas with lost details. Overall, our method produces results that are more accurate and closer to the ground truth.

Fig. 5 Visual comparison of different methods on the testing data from Chen21.
D. Ablation Studies
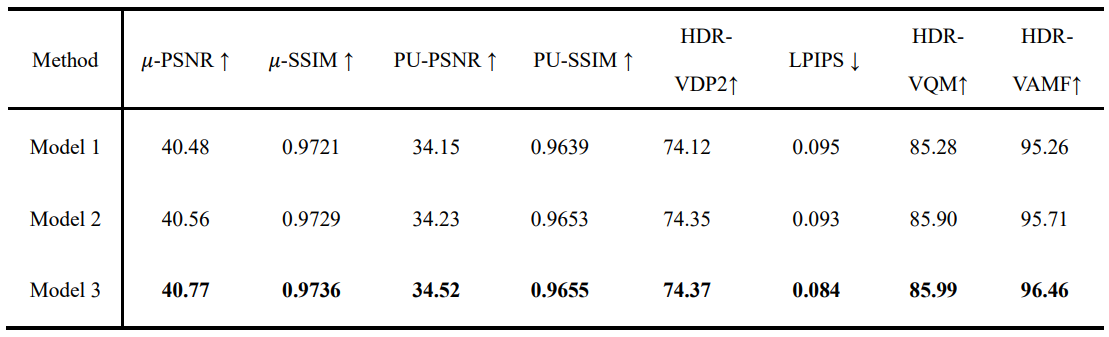
To evaluate the effectiveness of each component in our HDRMamba network, we conducted a comprehensive ablation study. The model configuration is shown in Table 2. Table 3 and Table 4 presents the results of this analysis, comparing three model variations. Our baseline model, Model 1, incorporates both the intra-frame four-directional SSM and the cross-frame bidirectional SSM. Our final model, Model 2, further refines the architecture by incorporating prompt-tuning. This addition shows incremental improvements across most metrics. The enhanced performance in these areas suggests that prompt-tuning allows the model to better adapt to varying exposure conditions. This ablation study demonstrates that each component contributes to the overall performance of HDRMamba.
TABLE. 2 Model configuration of ablation studies.
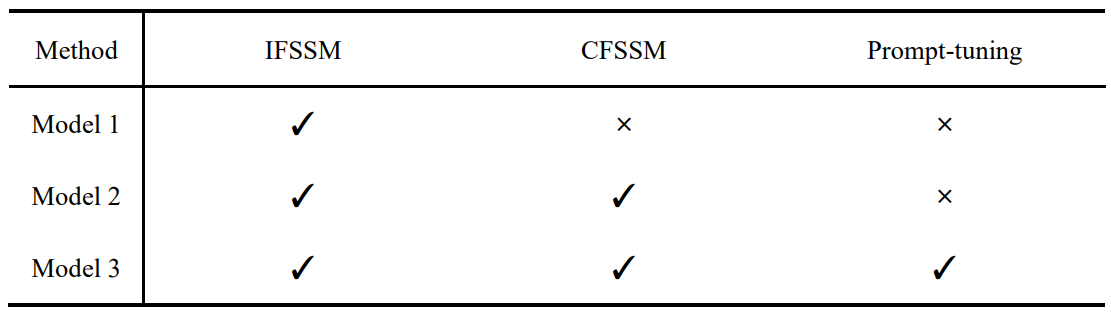
TABLE. 3 Comparison of ablation study results in dynamic scenes in Chen21.
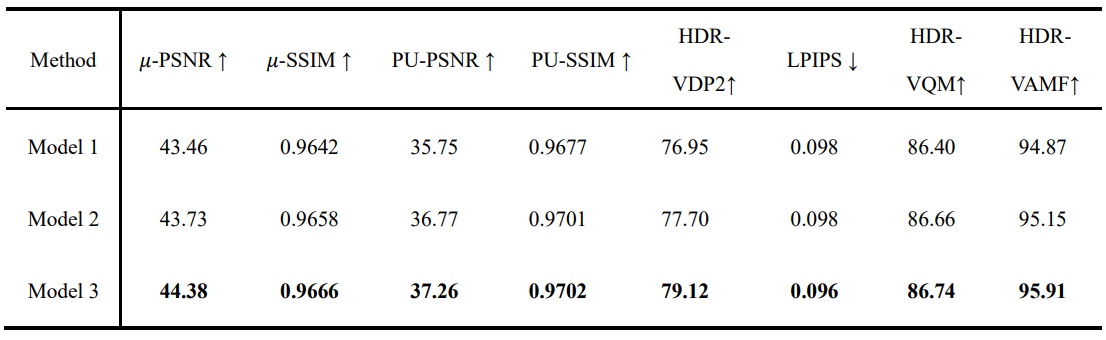
TABLE. 4 Comparison of ablation study results in static scenes in Chen21.
Conclusion
In this paper, we introduced HDRMamba, a novel HDR video reconstruction method that effectively balances reconstruction quality with computational efficiency. Our evaluations demonstrate that HDRMamba outperforms current state-of-the-art methods across various metrics. The architecture leverages a combination of intra-frame four-directional SSM and cross-frame bidirectional SSM to enhance spatial and temporal information processing, leading to superior handling of dynamic scenes and ghosting artifacts. Moreover, the incorporation of prompt-tuning enables HDRMamba to adapt flexibly to varying exposure conditions, further improving reconstruction quality. Overall, HDRMamba offers a robust and efficient approach that meets the demands of both quality and performance in real-world scenarios.