Dynamic Point Cloud Geometry Compression Using Conditional Residual Coding
Dynamic Point Cloud Geometry Compression
Using Conditional Residual Coding
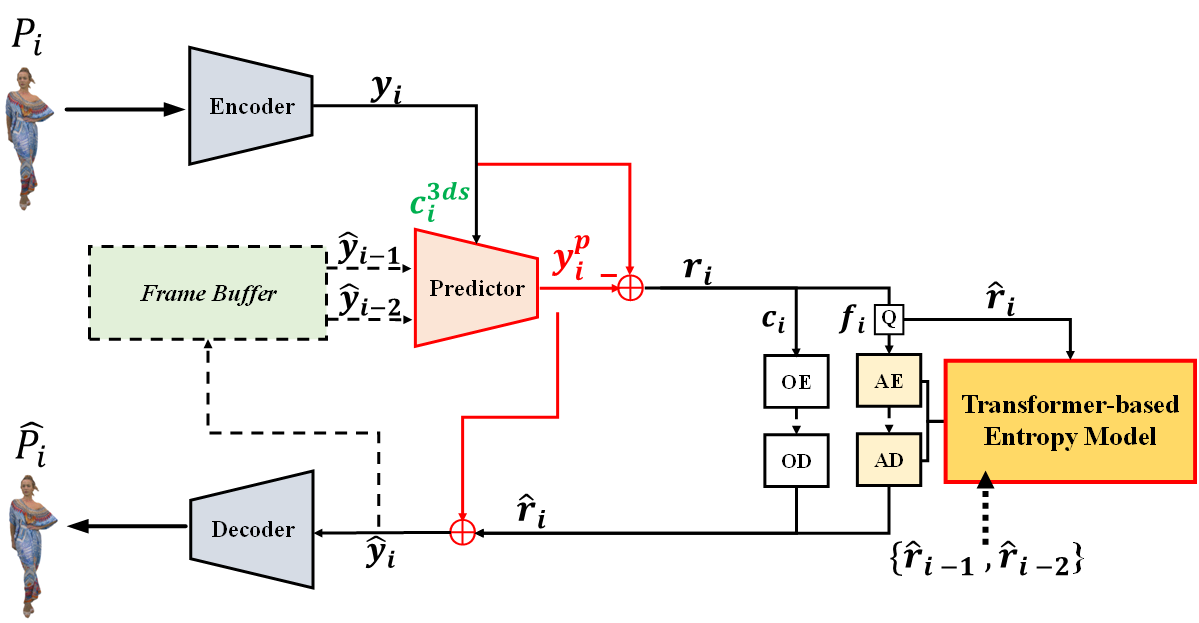
Fig. 1: The network architecture of proposed CRC-DPCGC.
ABTRACT
Dynamic point cloud compression faces significant challenges due to the inherent unstructured and sparse nature of point clouds, requiring efficient modeling of temporal context information. Current approaches often fall short in effectively capturing and utilizing inter-frame dependencies. We presents a novel conditional residual coding technique for dynamic point cloud geometry compression, specifically designed to address this challenge. Our method exploits spatial-temporal features through the design of a predictor module and a Transformer-based entropy model. The predictor module transfers features from previous point cloud frames to the current frame, efficiently generating residual features. The Transformer entropy model employs a conditional coding strategy, utilizing cross-attention between the current frame and its predecessors, leading to a more precise bit estimation. Extensive experimental results demonstrate that our proposed method outperforms existing dynamic point cloud geometry compression techniques, including both rule-based and learning-based approaches, showcasing its effectiveness in capturing and utilizing temporal information.
PROPOSED METHOD
The proposed architecture, illustrated in Fig. 1, consists of three key components: main encoder/decoder, predictor, and Transformer-based entropy model (TEM). The input point cloud
A.Predictor
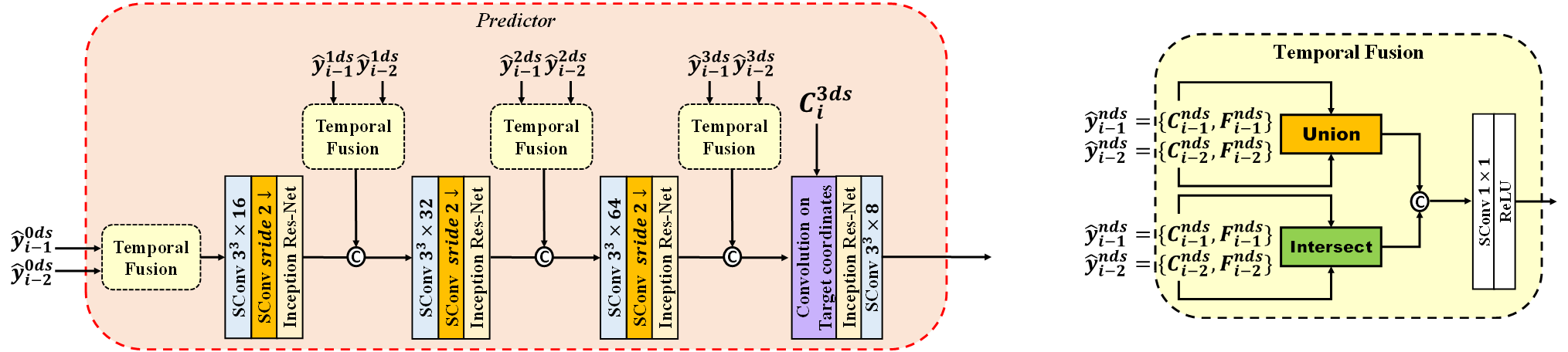
Fig. 2: The network architecture of proposed Predictor Module & Temporal Fusion Module
A temporal fusion module is employed to effectively utilize spatiotemporal features from two previous frames , as show in Fig. 2 . This module intersects and unifies features across previous frames, enriching feature information and extracting essential information common across different frames. These features are then concatenated at each scale, achieving comprehensive spatiotemporal fusion. Finally, “convolution on target coordinates” maps features from the previous frames coordinates to those of the current frame, enabling the prediction of the current frame's features using multi-scale coordinates from previous frames.
B.Transformer-based Entropy Model
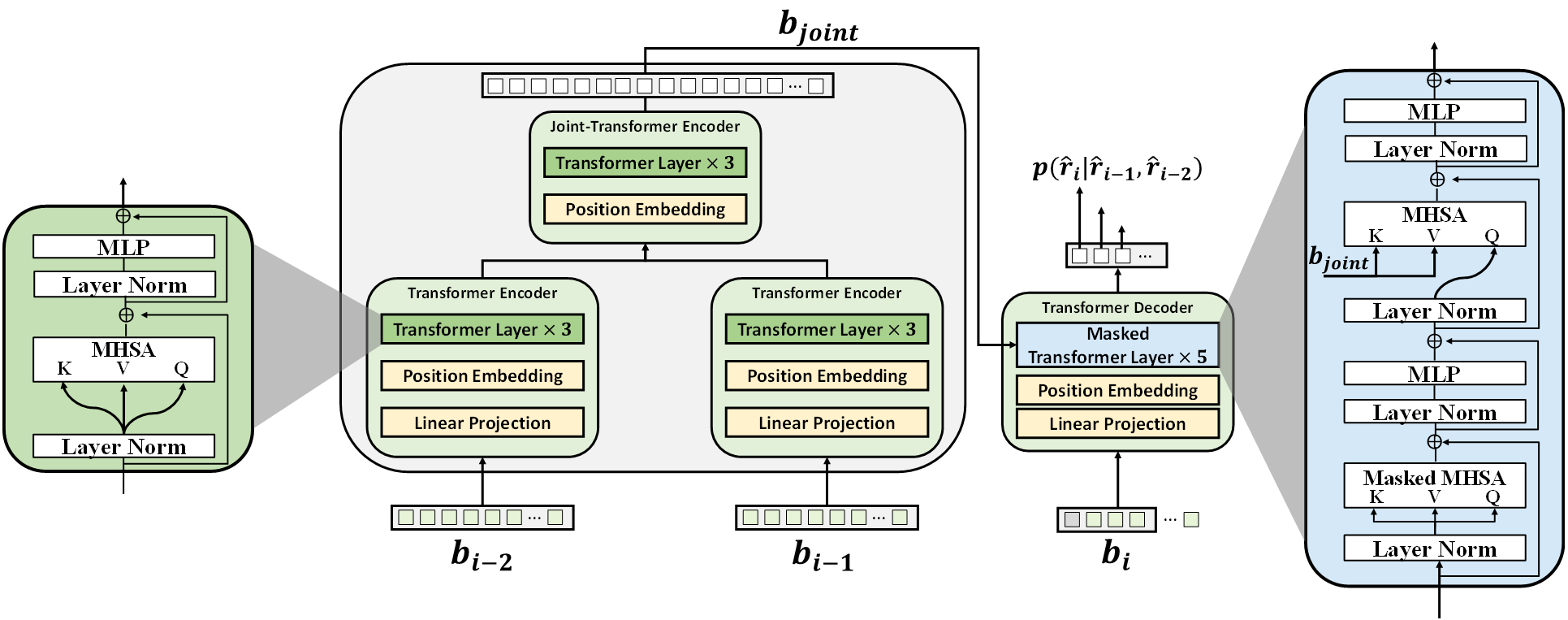
Fig. 3: The network architecture of proposed Transformer-based Entropy Model
To build an accurate context model for dynamic point cloud compression, it is crucial to leverage temporal relationships between neighboring point cloud frames. Directly inputting large-scale feature representations into a transformer incurs high computational costs. We introduce a Transformer-based Entropy Model (TEM) to encode the residual features as shown in Fig.3 . However, the inherent unordered and sparse nature of point clouds presents a challenge compared to video coding. To tackle this, we first conduct a Morton scan on the 3D points, transforming spatially irregular 3D points into a one-dimensional (1D) sequence, which serves as input to the Transformer.
EXPERIMENT
A.Dataset
For training, we utilize the 8iVoxelized Full Bodies (8iVFB) dataset comprising four sequences: longdress, loot, redandblack, as shown in Fig.4 , and soldier, each with 300 frames. All sequences are quantized to 9-bit geometry precision. For testing, we employ the Owlii dynamic human sequence dataset containing four sequences: basketball, dancer, exercise, and model, as shown in Fig.5, all quantized to 10-bit geometry precision. The division of training and testing samples adheres to the Exploration Experiment (EE) guidelines recommended by the MPEG AI-PCC group.

Fig. 4:Training Dataset. 8iVoxelized Full Bodies (8iVFB)

Fig. 5:Testing Dataset. Owlii dynamic human sequence
B.Performance Comparison
We evaluated the performance of our proposed method against VPCCv18 (as specified in MPEG EE 5.3), and also learned dynamic point cloud geometry compression methods, including DPCC-SC, SparsePCGCv3, D-DPCC, Hie-ME/MC and DPCC-STTM. And also comparing the result with Mamba-PCGC. Rate-distortion curves for different methods are presented in Fig.6 , and corresponding BD-Rate gains are shown in Table.1 and Table.2.
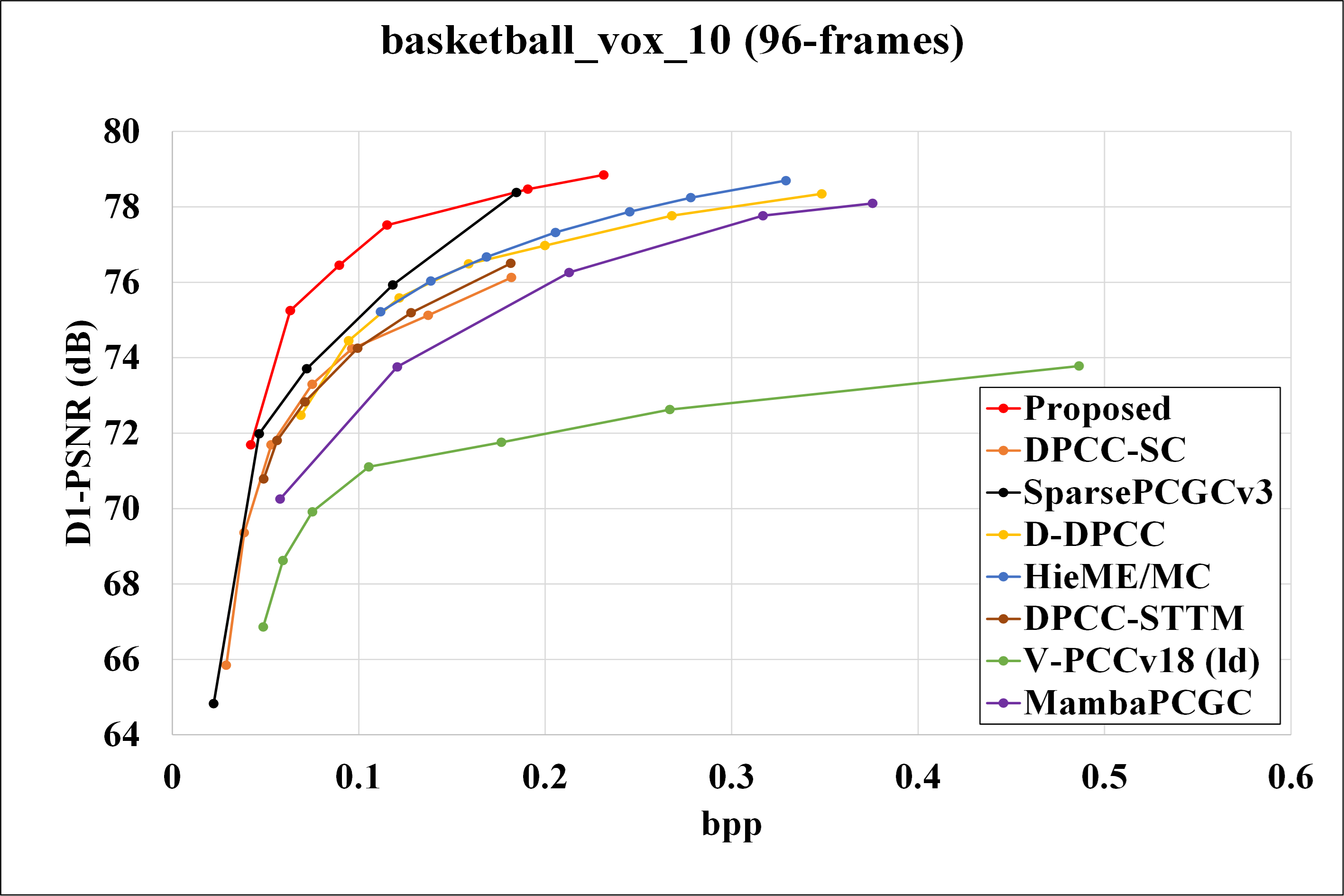
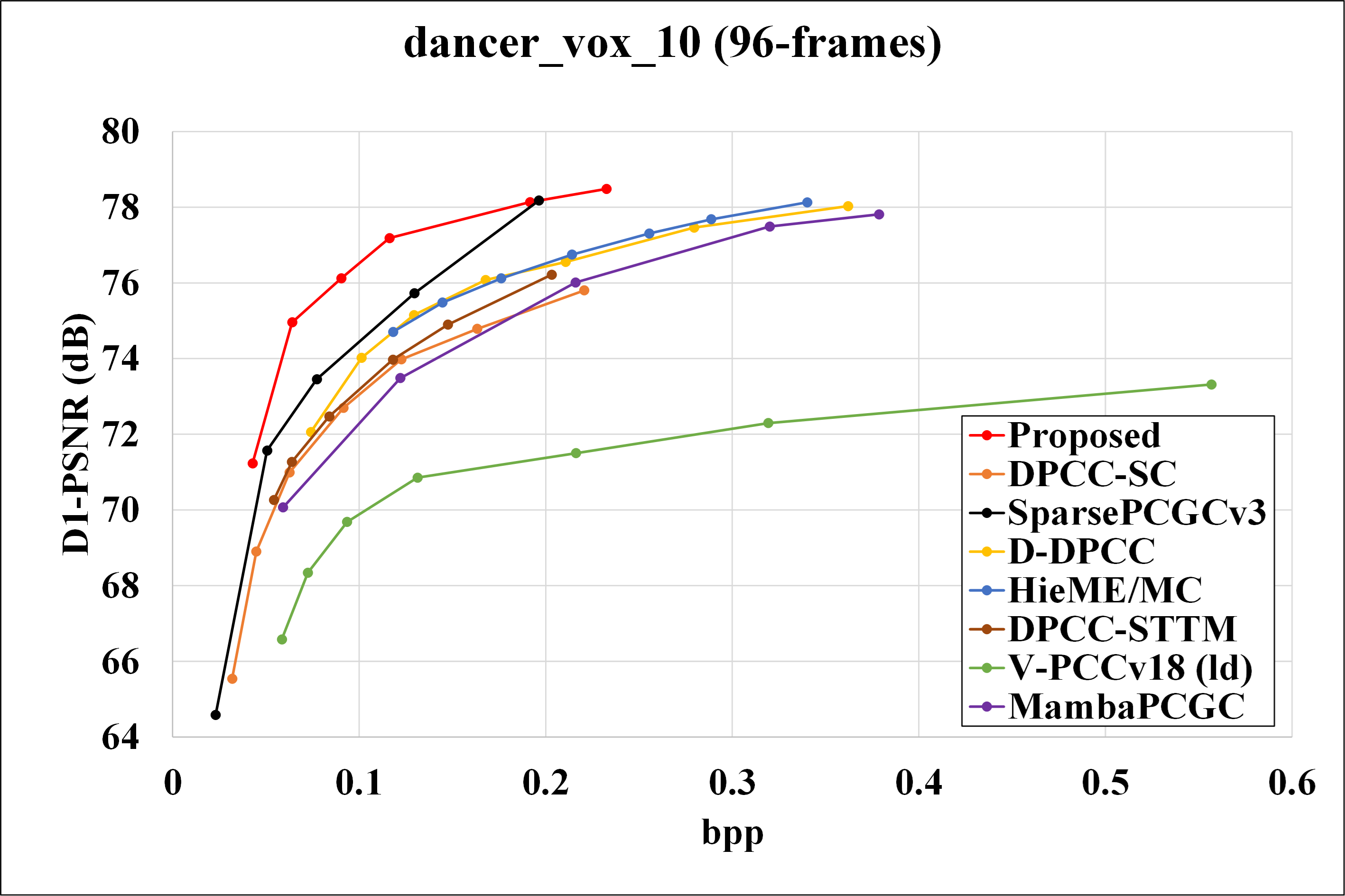
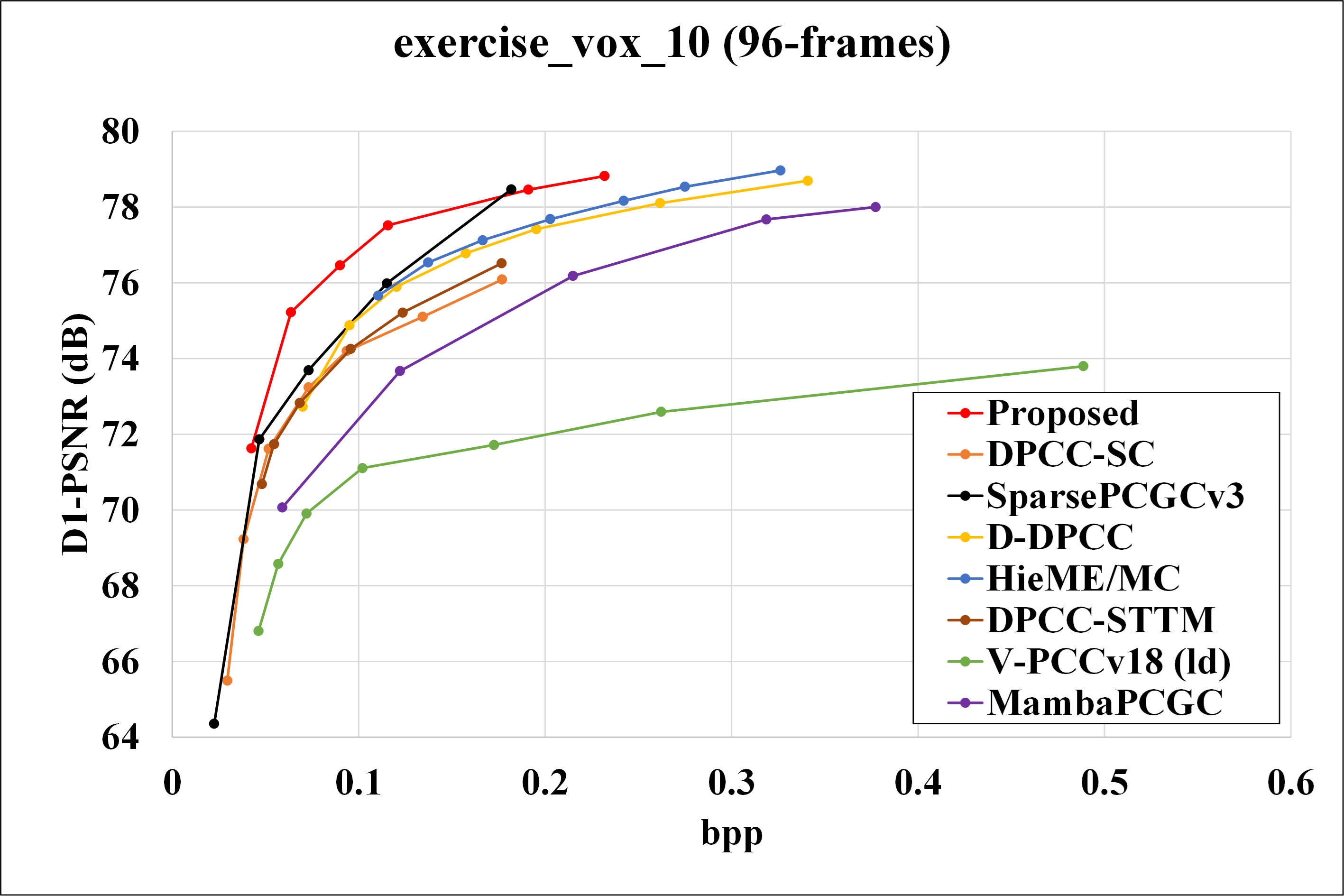
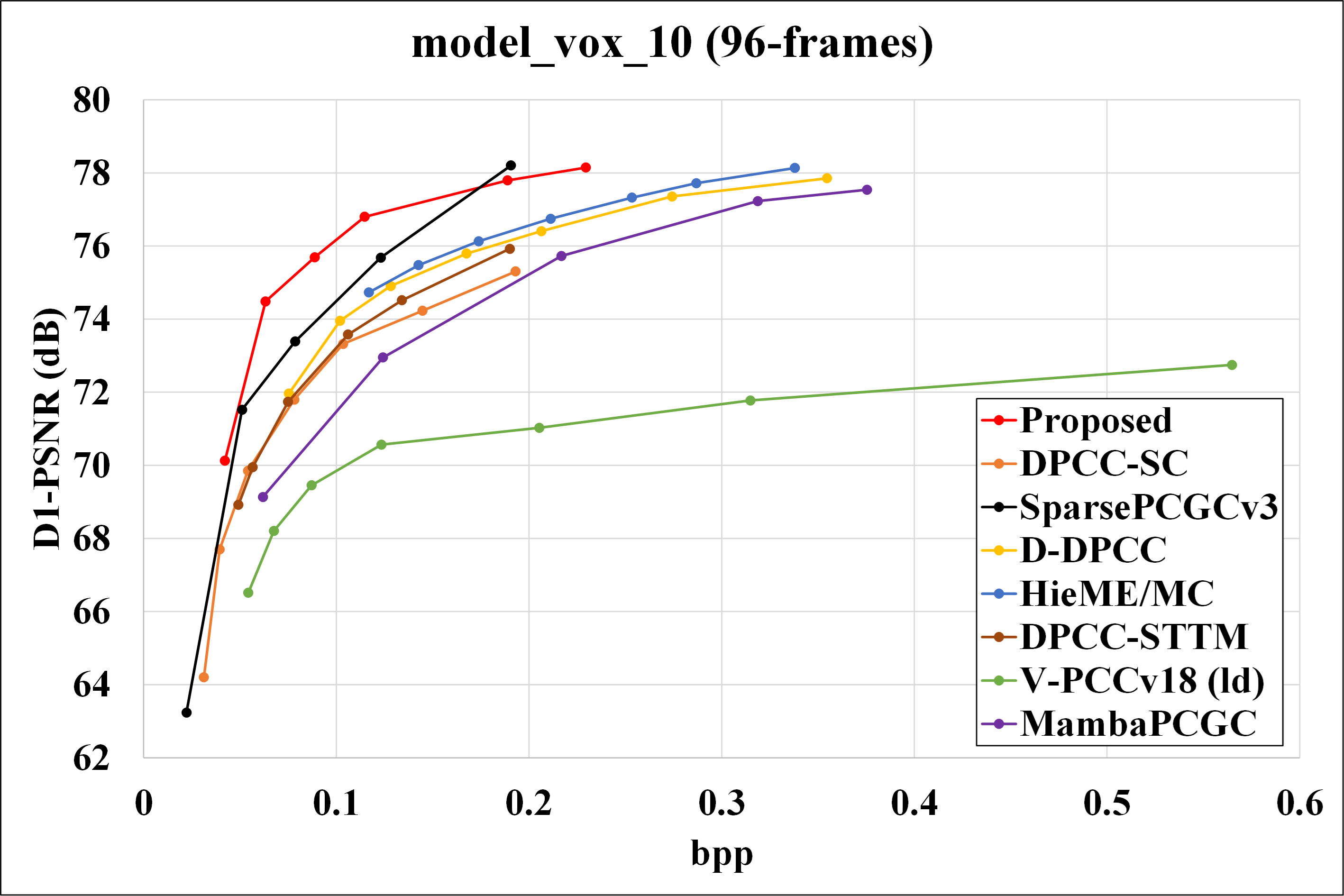
Fig. 6: R-D curves for basketball, dancer, exercise, model.
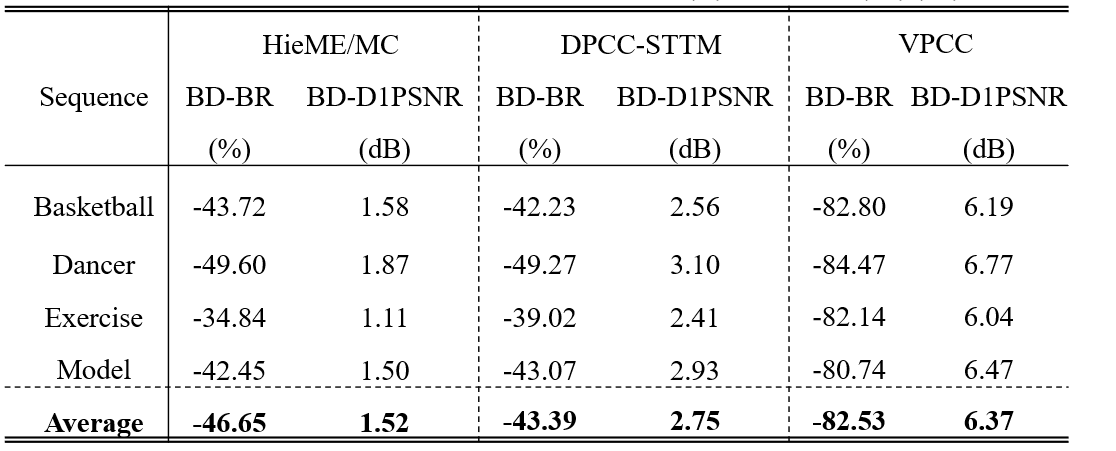
Our proposed method significantly outperforms VPCCv18 across all testing sequences, achieving an average BD-Rate gain of 82.53%. Notably, the dancer sequence exhibits the highest BD-Rate gain compared to other sequences. Furthermore, our method achieves up to 43.39% BD-Rate gain compared to other existing learning-based solutions for DPCGC.
Table. 1: BD-Rate(%) and BD-PSNR(dB) with respect to other method
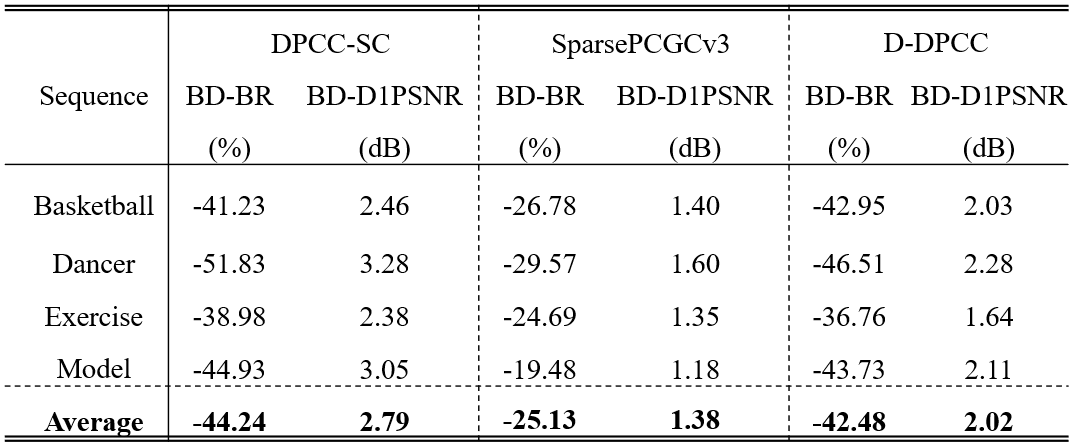
Table. 2: BD-Rate(%) and BD-PSNR(dB) with respect to other method